












语音识别(ASR)上行链路:从麦克风到文字的完整技术链路
1. 文档目标
系统讲清楚 ASR(Automatic Speech Recognition,自动语音识别)上行链路涉及的业务流程、技术原理、背景知识以及每个参数和设计决策的原因:
麦克风采集 → 音频前端处理(AEC/NS/VAD) → OPUS 编码 → 网络传输 → 服务端 STT → 识别文字返回设备本文不涉及具体代码实现,只讲业务流、技术原理和参数设计。 与本文配套的下行链路文档:
tts-opus-playback-pipeline.md
2. 整体业务流全景
2.1 完整链路图
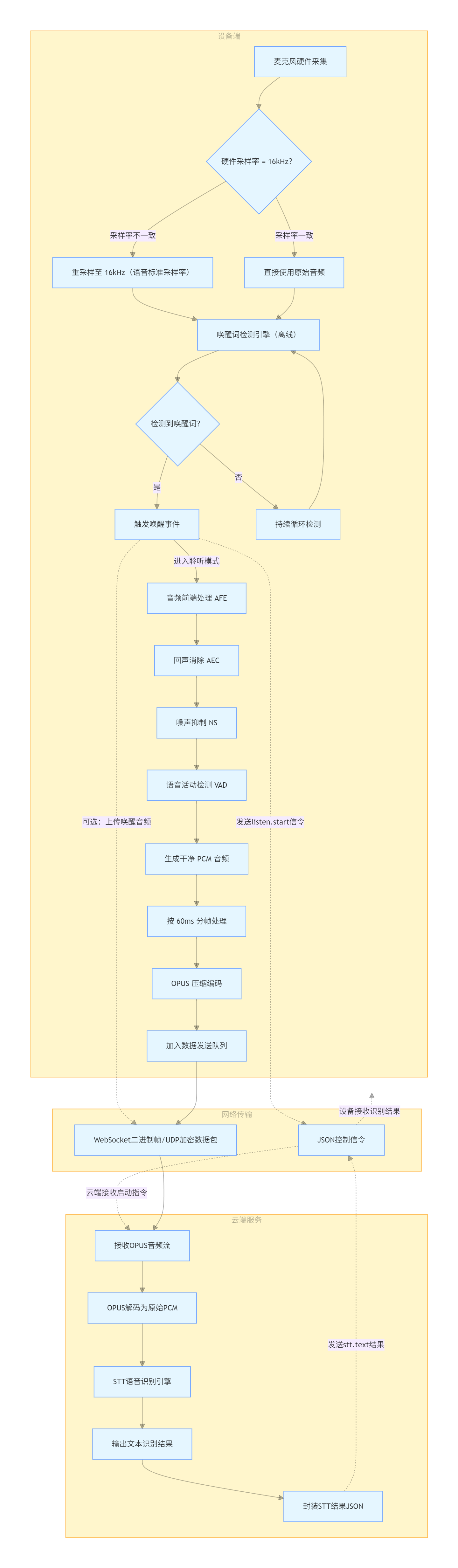
flowchart TD
subgraph 设备端
A[麦克风硬件采集]
B{"硬件采样率 = 16kHz?"}
B1["重采样到 16kHz"]
B2[直接使用]
C[唤醒词检测引擎]
D{"检测到唤醒词?"}
D1[触发唤醒事件]
D2[继续检测]
E[音频前端处理 AFE]
E1[回声消除 AEC]
E2[噪声抑制 NS]
E3[语音活动检测 VAD]
F[处理后的干净 PCM]
G["按 60ms 分帧"]
H[OPUS 编码压缩]
I[送入发送队列]
end
subgraph 网络传输
J[WebSocket 二进制帧 或 UDP 加密包]
K[JSON 控制消息]
end
subgraph 云端服务
L[接收 OPUS 音频流]
M[OPUS 解码为 PCM]
N[STT 语音识别引擎]
O[输出识别文字]
P[返回 stt JSON 消息给设备]
end
A --> B
B -->|不一致| B1 --> C
B -->|一致| B2 --> C
C --> D
D -->|否| D2 --> C
D -->|是| D1
D1 -."打开音频通道".-> K
D1 -."可选:发送唤醒词音频".-> J
C -."切换到聆听模式".-> E
E --> E1 --> E2 --> E3
E3 --> F --> G --> H --> I --> J
K -."listen.start".-> L
J --> L --> M --> N --> O --> P
P -."stt.text".-> K2.2 核心要点
- 语音识别在云端完成,设备端不做 STT
- 设备端负责:麦克风采集 → 音频前端处理 → OPUS 编码 → 上传
- 整条上行链路有两个阶段:
- 唤醒阶段:设备端本地运行唤醒词检测模型,不联网
- 聆听阶段:音频经前端处理后编码上传,服务端做 STT
- 唤醒词检测和音频前端处理是两个独立模块,可以单独启用/禁用
- 设备同时发送两路数据给服务端:
- JSON 控制消息:
listen.start、listen.stop、listen.detect - OPUS 二进制音频包:真正的语音数据
- JSON 控制消息:
3. 每个环节的技术原理
3.1 麦克风采集
做什么
通过 I2S 接口或板级音频 Codec 芯片,从麦克风持续采集原始 PCM 音频数据。
采集参数
| 参数 | 典型值 | 说明 |
|---|---|---|
| 硬件采样率 | 因板而异(16kHz / 48kHz 等) | Codec 芯片的原生采样率 |
| 目标采样率 | 16000 Hz | 统一重采样到 16kHz |
| 位深 | 16 bit(有符号整数) | 标准语音处理位深 |
| 通道数 | 1 或 2 | 单麦/双麦,部分板子还有参考通道 |
| 每次读取 | 10ms(160 采样点) | 喂给唤醒词和音频处理器的最小粒度 |
为什么统一重采样到 16kHz
- 唤醒词模型和语音识别模型都以 16kHz 为标准输入
- OPUS 编码器配置为 16kHz
- 统一采样率简化整条链路的缓冲区管理
- 如果硬件采样率不是 16kHz,在采集后立即做重采样转换
通道处理
- 单麦克风:直接使用
- 双通道(单麦 + 参考通道):麦克风通道用于语音采集,参考通道(来自扬声器回采)用于回声消除 AEC
- 双麦克风:用于波束成形等高级前端处理
- 最终喂给唤醒词和编码器的都是单声道 16kHz PCM
3.2 唤醒词检测
背景
语音助手需要一个低功耗的本地触发机制。用户说出唤醒词(如"小智同学"),设备才开始联网进行语音识别。
为什么在本地做唤醒词检测
- 隐私:不联网就不上传任何音频
- 低延迟:本地检测比云端快几百毫秒
- 省电:不需要一直维持网络连接
- 省带宽:只有唤醒后才开始上传
三种唤醒词引擎
本项目支持三种唤醒词检测方案,适配不同硬件能力:
| 引擎 | 适用芯片 | 特点 |
|---|---|---|
| AFE 唤醒词 | ESP32-S3 / ESP32-P4 | 集成音频前端(AEC + NS),唤醒检测与音频前端处理合一 |
| 自定义唤醒词 | ESP32-S3 / ESP32-P4 | 基于 MultiNet 命令词模型,支持自定义唤醒词和命令词 |
| 轻量唤醒词 | ESP32 等较弱芯片 | 仅做唤醒词检测,无音频前端处理,资源占用最小 |
唤醒词检测流程
麦克风 PCM(10ms 一帧)
│
▼
送入唤醒词引擎缓冲区
│
▼
累积到引擎所需的块大小(如 30ms / 512 采样)
│
▼
执行检测推理
│
├── 未检测到 → 继续累积下一帧
│
└── 检测到唤醒词!
│
├── 回调通知应用层
├── 可选:编码最近 ~2 秒的音频为 OPUS 发给服务端
└── 应用层开始建立连接 + 切换到聆听模式唤醒词音频回传(可选)
检测到唤醒词时,引擎会保留最近约 2 秒的音频数据。这些数据可以被编码为 OPUS 后发给服务端,好处是:
- 服务端可以做说话人识别(是谁在叫唤醒词)
- 服务端可以做唤醒词确认(减少误唤醒)
- 服务端可以直接用于 STT(用户可能唤醒词后紧跟着说了指令)
3.3 音频前端处理(AFE)
背景
真实环境中的麦克风采集到的不是干净的人声,而是混合了:
- 回声:扬声器播放的声音被麦克风重新采集
- 环境噪声:风扇、空调、电视等背景声
- 混响:房间墙壁反射的声音
这些干扰会严重影响语音识别准确率。音频前端处理(Audio Front-End, AFE)的目标是在发送给 STT 之前清理音频。
三大核心模块
┌──────────────────────────────────────────────────┐
│ 音频前端处理 (AFE)│
││
│┌────────────┐┌────────────┐┌─────────────┐ │
││AEC ││NS││VAD│ │
││回声消除 │→│噪声抑制 │→│语音活动检测 │ │
│└────────────┘└────────────┘└─────────────┘ │
│ ↑ │
│参考信号(扬声器回采)│
└──────────────────────────────────────────────────┘3.3.1 AEC 回声消除
问题:当设备一边播放 AI 回复一边监听用户语音时(实时对话模式),扬声器声音会被麦克风采到,服务端 STT 会把 AI 自己说的话也识别出来。
原理:AEC 利用扬声器的输出信号作为"参考",从麦克风信号中估计并减去回声成分,只保留用户的真实语音。
两种 AEC 方案:
| 方案 | 执行位置 | 工作方式 | 优点 | 缺点 |
|---|---|---|---|---|
| 设备端 AEC | 设备端 AFE | 用扬声器参考通道做本地回声消除 | 延迟最低,不依赖网络 | 需要硬件支持参考通道,对板级设计要求高 |
| 服务端 AEC | 云端 | 设备上传音频时带 timestamp,服务端用回放时间戳对齐做消除 | 对硬件无要求 | 依赖网络延迟稳定,效果不如设备端 |
不使用 AEC 时:
- 设备在播放 AI 回复时不监听麦克风
- 播放结束后才切回聆听模式
- 对话节奏是严格的"一问一答"轮替,不能打断
3.3.2 NS 噪声抑制
问题:环境噪声降低 STT 识别准确率。
两种方案:
| 方案 | 说明 |
|---|---|
| 传统 NS | 基于频谱减法等信号处理算法,轻量快速 |
| 神经网络 NS | 基于 NSNet 等深度学习模型,效果更好但 CPU 开销更大 |
项目在 AFE 中优先使用神经网络 NS(如果模型存在),否则关闭 NS。
3.3.3 VAD 语音活动检测
做什么:判断当前音频帧是"有人在说话"还是"静默/噪声"。
输出:二值状态 —— SPEECH(说话中)或 SILENCE(静默)。
作用:
- 自动停止模式下:VAD 检测到持续静默后,设备自动结束聆听,触发服务端 STT 处理
- LED 反馈:聆听时根据 VAD 状态变化更新 LED 指示灯
- 服务端辅助:服务端也可以用 VAD 信息决定何时开始/结束识别
AFE 的两种运行场景
| 场景 | AFE 类型 | 用途 |
|---|---|---|
| 唤醒检测阶段 | AFE_TYPE_SR(语音识别型) | 集成唤醒词检测,需要运行 WakeNet 模型 |
| 聆听/通信阶段 | AFE_TYPE_VC(语音通信型) | 专注于 AEC + NS + VAD,输出干净音频给编码器 |
两个阶段使用不同的 AFE 实例,因为:
- 唤醒阶段需要跑唤醒词模型,聆听阶段不需要
- 聆听阶段需要输出固定帧长的 PCM(60ms),唤醒阶段的帧长由模型决定
- 分开管理可以独立启停,不互相干扰
无 AFE 的回退方案
如果设备不支持 AFE(资源不足),系统退化为直通模式:
- 麦克风 PCM 直接分帧,不做任何前端处理
- 不支持 AEC(不能在播放时同时听)
- 不支持 VAD(不能自动停止)
- 不支持 NS(噪声直接上传)
- 只做立体声转单声道和帧长对齐
3.4 OPUS 编码
做什么
将 AFE 处理后的干净 PCM 音频帧压缩为 OPUS 格式,减小网络传输数据量。
编码流程
AFE 输出干净 PCM(60ms = 960 采样点)
│
▼
送入编码队列(最多 2 个任务排队)
│
▼
编解码任务取出 PCM 帧
│
▼
OPUS 编码器压缩
│
▼
OPUS 包(约 40~120 字节)送入发送队列
│
▼
主循环触发 → 协议层发送编码参数(与下行完全一致)
| 参数 | 值 | 原因 |
|---|---|---|
| 采样率 | 16kHz | 语音频带甜点,STT 模型标准 |
| 通道 | Mono | 语音不需立体声 |
| 帧长 | 60ms | 压缩效率与嵌入式资源的折中 |
| 码率 | Auto | 自适应内容复杂度 |
| 复杂度 | 0 | MCU 实时约束,省 CPU 省电 |
| FEC | 关闭 | WebSocket/TCP 已可靠,UDP 接受偶尔丢帧 |
| DTX | 开启 | 静默段不发数据,省带宽省电 |
| VBR | 开启 | 语音动态范围大,码率花在刀刃上 |
上下行参数完全统一的好处:编解码器复用、队列结构复用、协议一致、内存可预测。 详细参数解释见
tts-opus-playback-pipeline.md第 4 章。
为什么编码队列最多只排 2 个任务
- 编码是 CPU 密集操作,如果排队太多说明编码速度跟不上采集速度
- 限制为 2 个可以背压到音频处理器,避免内存无限增长
- 同时保证网络抖动时有 1 帧的缓冲余量
3.5 时间戳与服务端 AEC
背景
在服务端 AEC 方案中,服务端需要知道每个上行音频帧对应的设备端时刻,才能与同一时刻下发的回放音频做对齐消除。
工作方式
设备端:
收到服务端下行音频包 → 记录 timestamp → 放入时间戳队列
编码上行音频时 → 从时间戳队列取出 timestamp → 附加到 OPUS 包
服务端:
收到上行音频包的 timestamp
查找同一 timestamp 的下行音频
执行回声消除这样服务端就能知道"设备在播放哪段音频的同时录到了这段麦克风信号",从而正确消除回声。
3.6 网络发送
发送队列
编码后的 OPUS 包进入发送队列,队列上限约 2400ms(约 40 个 60ms 的包)。主循环检测到队列有数据后,逐包通过协议层发送。
两种传输方案
WebSocket 方案:
OPUS 包 → 加上协议头(版本/类型/时间戳/大小)→ WebSocket 二进制帧发送- V1:裸 OPUS payload
- V2:带 timestamp 和 payload_size 头(用于服务端 AEC)
- V3:轻量头,只带 type 和 payload_size
MQTT + UDP 方案:
OPUS 包 → AES-128-CTR 加密 → 加上 UDP 包头(类型/标志/SSRC/时间戳/序列号)→ UDP 发送- 控制消息走 MQTT/TLS
- 音频数据走 UDP,更低延迟
- 加密防窃听,序列号防重放
3.7 服务端 STT 语音识别
做什么
服务端接收 OPUS 音频流,解码为 PCM,送入 STT 引擎转换为文字。
STT 的工作模式
服务端 STT 通常支持流式识别:
- 不需要等整段话说完
- 一边收到音频一边输出中间结果(partial results)
- 用户说完后输出最终结果(final result)
识别结果返回
服务端将识别出的文字通过 JSON 消息返回设备:
{"type": "stt", "text": "今天天气怎么样"}设备收到后在屏幕上显示为用户发言的字幕。
4. 聆听模式详解
4.1 三种聆听模式
设备进入聆听状态时,需要告诉服务端采用哪种聆听模式:
| 模式 | 名称 | JSON 值 | 触发结束的方式 | 需要 AEC |
|---|---|---|---|---|
| 自动停止 | AutoStop | "auto" | VAD 检测到持续静默后自动结束 | ❌ |
| 手动停止 | ManualStop | "manual" | 用户按键/再次唤醒才结束 | ❌ |
| 实时对话 | Realtime | "realtime" | 不主动结束,持续双向通信 | ✅ |
4.2 模式选择逻辑
AEC 已开启?
│
├── 是 → 默认使用 Realtime 模式(全双工对话)
│
└── 否 → 默认使用 AutoStop 模式(半双工轮替)AutoStop 模式(最常用)
用户说话 ──► VAD=SPEECH ──► 用户停顿 ──► VAD=SILENCE 持续一段时间
│
▼
设备自动结束聆听
服务端输出最终识别结果
进入 LLM 处理 → TTS 回复Realtime 模式(需要 AEC)
用户说话 ──────────────────────────────────────────►
AI 回复◄──────────────────────────────────────────
(可以随时打断,双向同时进行)- 设备在 AI 播放回复的同时仍然监听麦克风
- AEC 消除掉扬声器回声,只保留用户语音
- 用户可以随时打断 AI
4.3 聆听相关的 JSON 消息协议
设备 → 服务端
| 消息 | 含义 |
|---|---|
{"type":"listen", "state":"detect", "text":"小智同学"} | 唤醒词检测到,附带唤醒词文本 |
{"type":"listen", "state":"start", "mode":"auto"} | 开始聆听,告知模式 |
{"type":"listen", "state":"stop"} | 停止聆听 |
{"type":"abort", "reason":"wake_word_detected"} | 打断当前 AI 回复 |
服务端 → 设备
| 消息 | 含义 |
|---|---|
{"type":"stt", "text":"用户说的话"} | STT 识别结果,设备显示为用户字幕 |
5. 设备状态机与 ASR 的关系
5.1 状态流转图
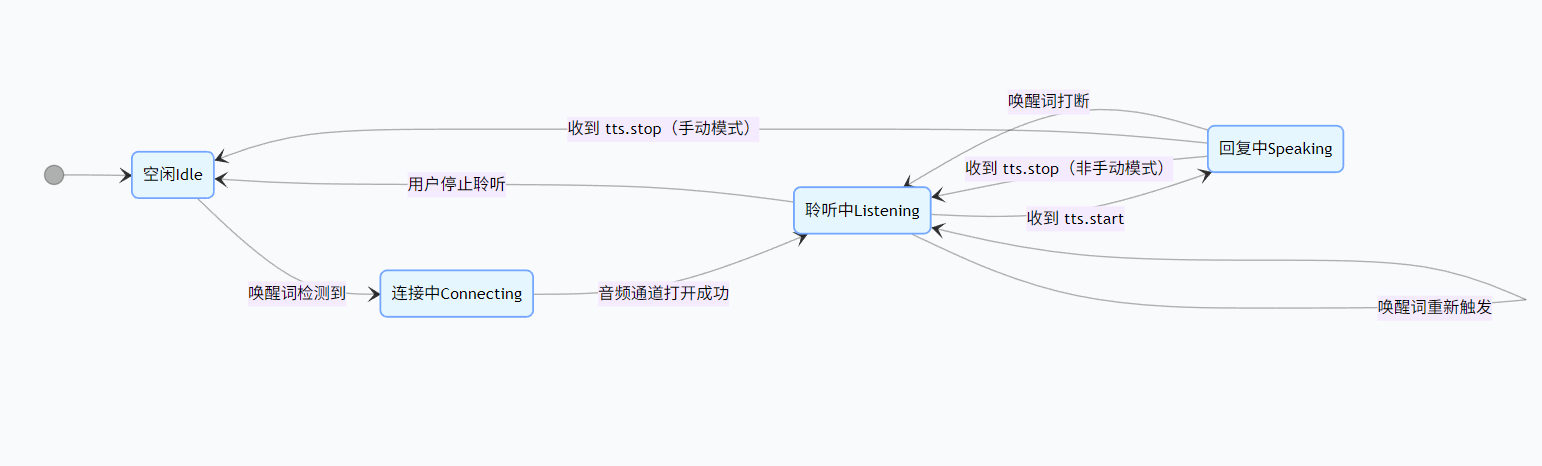
stateDiagram-v2
[*] --> 空闲Idle
空闲Idle --> 连接中Connecting : 唤醒词检测到
连接中Connecting --> 聆听中Listening : 音频通道打开成功
聆听中Listening --> 回复中Speaking : 收到 tts.start
回复中Speaking --> 聆听中Listening : 收到 tts.stop(非手动模式)
回复中Speaking --> 空闲Idle : 收到 tts.stop(手动模式)
聆听中Listening --> 空闲Idle : 用户停止聆听
回复中Speaking --> 聆听中Listening : 唤醒词打断
聆听中Listening --> 聆听中Listening : 唤醒词重新触发5.2 各状态下的音频模块启停
| 设备状态 | 唤醒词检测 | 音频前端处理 | OPUS 编码上传 | OPUS 解码播放 |
|---|---|---|---|---|
| 空闲 | ✅ 运行 | ❌ 停止 | ❌ 停止 | ❌ 停止 |
| 连接中 | ❌ 停止 | ❌ 停止 | ❌ 停止 | ❌ 停止 |
| 聆听中 | 视配置 | ✅ 运行 | ✅ 运行 | ❌ 停止 |
| 回复中 | 视配置 | 视模式 | 视模式 | ✅ 运行 |
- 聆听中:唤醒词检测默认关闭(避免自己说的话触发唤醒),但如果使用 AFE 唤醒词引擎可以配置为同时运行
- 回复中 + Realtime 模式:音频前端处理和编码上传保持运行(全双工)
- 回复中 + 非 Realtime 模式:音频前端处理和编码上传停止(半双工)
6. AEC 回声消除深入
6.1 为什么 AEC 是 ASR 链路中最复杂的部分
在语音助手场景中,最理想的体验是随时可以打断 AI。但这要求设备在播放 AI 回复的同时监听麦克风,而此时:
- 扬声器声音 >> 用户声音(扬声器就在麦克风旁边)
- 不消除回声的话,STT 会把 AI 自己说的话识别出来
- 甚至会形成"AI 自己触发自己"的死循环
AEC 的基本原理
参考信号(扬声器输出)
│
▼
┌──────────────────┐
│ 自适应滤波器 │ ← 估计回声路径
└──────────────────┘
│
▼ 估计的回声
麦克风信号 ─────⊖──────► 残差信号(≈ 纯用户语音)
减去估计回声- 用扬声器的输出信号作为参考
- 自适应滤波器学习"扬声器到麦克风"的传递路径
- 用学到的路径预测麦克风会采到的回声
- 从麦克风信号中减去预测的回声
- 残差就是用户的真实语音
6.2 设备端 AEC vs 服务端 AEC
| 维度 | 设备端 AEC | 服务端 AEC |
|---|---|---|
| 执行位置 | 设备端 AFE 模块 | 云端 |
| 参考信号来源 | 硬件回采(I2S 回环/Codec 回采) | 服务端下行音频的时间戳对齐 |
| 延迟 | 极低(本地处理) | 受网络延迟影响 |
| 消除效果 | 好(参考信号精确对齐) | 一般(网络抖动导致对齐误差) |
| 硬件要求 | 需要 Codec 支持参考通道输出 | 无特殊要求 |
| 稳定性 | 成熟 | 标注为不稳定(Unstable) |
6.3 不使用 AEC 时的对话模式
用户说话 → 设备上传 → 服务端 STT → LLM → TTS
↓
用户等待 ← 设备播放 AI 回复 ← OPUS 下发
↓
播放结束
↓
设备重新进入聆听 → 用户可以继续说话这是半双工轮替模式:一方说话时另一方必须等待。用户体验不如全双工自然,但实现简单可靠。
7. 完整的一次对话时序
7.1 从唤醒到收到识别结果
时间 ─────────────────────────────────────────────────────────────────────►
设备端:
① 麦克风持续采集,喂给唤醒词引擎
② 用户说:"小智同学"
③ 唤醒词引擎检测到 → 触发唤醒事件
④ 编码最近 ~2秒 唤醒词音频为 OPUS(可选)
⑤ 打开音频通道(WebSocket 连接 / MQTT+UDP 建立)
⑥ 发送 hello 握手,协商音频参数
⑦ 发送唤醒词 OPUS 数据(可选)
⑧ 发送 {"type":"listen", "state":"detect", "text":"小智同学"}
⑨ 切换到聆听状态
⑩ 启动音频前端处理(AFE)
⑪ 发送 {"type":"listen", "state":"start", "mode":"auto"}
⑫ 用户说:"今天天气怎么样"
⑬ AFE 处理 → OPUS 编码 → 连续发送 OPUS 包
⑭ VAD 检测到静默 → 自动结束
服务端:
⑮ 收到音频流 → OPUS 解码 → STT 识别
⑯ 返回 {"type":"stt", "text":"今天天气怎么样"}
⑰ 送入 LLM 生成回复
⑱ TTS 合成 → OPUS 编码 → 下发(进入下行链路)
设备端:
⑲ 收到 stt 消息 → 屏幕显示用户字幕
⑳ 收到 tts.start → 切换到回复中状态
㉑ 收到 OPUS 音频包 → 解码播放(下行链路)7.2 打断场景(Realtime 模式)
① AI 正在播放回复(回复中状态)
② 用户突然说话
③ AEC 消除扬声器回声,提取用户语音
④ 唤醒词引擎检测到唤醒词(或 VAD 检测到语音)
⑤ 发送 {"type":"abort", "reason":"wake_word_detected"}
⑥ 设备停止播放,切换到聆听
⑦ 开始新一轮语音上传8. 关键设计决策总结
8.1 为什么唤醒词检测和音频前端处理是两个独立模块
| 维度 | 唤醒词检测 | 音频前端处理 |
|---|---|---|
| 运行时机 | 空闲时一直运行 | 只在聆听时运行 |
| AFE 类型 | SR(语音识别型,集成 WakeNet) | VC(语音通信型,集成 AEC/NS/VAD) |
| 输出 | 检测事件(是/否) | 干净的 PCM 音频帧 |
| 帧长 | 由模型决定(~30ms) | 由编码器决定(60ms) |
| CPU 占用 | 适中 | 较高(特别是开启 AEC + NS) |
分开设计可以:
- 空闲时只跑轻量的唤醒词检测,省电
- 聆听时才启动重量级的 AFE 处理
- 独立启停,互不干扰
- 切换时重置重采样器,避免缓冲区残留
8.2 为什么麦克风采集用 10ms 粒度而编码用 60ms 粒度
- 10ms 采集:满足唤醒词模型和 AFE 引擎的喂入需求(它们通常需要更细粒度的输入)
- 60ms 编码:OPUS 编码器的帧长设置,60ms 是压缩效率和嵌入式资源的最佳折中
- AFE 处理器内部做帧长对齐:累积 AFE 输出的小帧,攒够 60ms(960 采样)后一次性输出给编码器
8.3 为什么发送队列上限是 ~2400ms
- 与解码队列对称:上下行队列使用相同的设计
- 应对网络抖动:短暂的网络卡顿不会丢失音频
- 内存可控:40 个 OPUS 包 ≈ 4KB,远小于同等时长的 PCM(77KB)
- 不过度缓冲:超过 2.4 秒说明网络严重卡顿,继续缓冲意义不大
8.4 为什么编码队列只允许 2 个任务
- 编码队列存的是 PCM 帧(1920 字节/帧),比 OPUS 包大得多
- 限制为 2 个任务控制内存峰值
- 背压机制:如果编码器处理不过来,会阻塞 AFE 输出,形成流量控制
- 正常情况下编码速度远快于实时(60ms 音频编码只需几毫秒),队列几乎不会积压
9. AFE 参数选择详解
9.1 音频前端处理(聆听阶段)参数
| 参数 | 值 | 原因 |
|---|---|---|
| AFE 类型 | VC(语音通信) | 聆听阶段不需要唤醒词检测,专注于音频清理 |
| AEC 模式 | VOIP_HIGH_PERF | 为 VoIP 场景优化的高性能回声消除 |
| VAD 模式 | VAD_MODE_0 | 最灵敏的 VAD 设置,不漏掉轻声说话 |
| VAD 最小噪声时长 | 100ms | 低于 100ms 的短暂噪声不触发 VAD 状态变化 |
| NS 模式 | 优先使用 NSNet(神经网络),否则关闭 | 神经网络降噪效果远好于传统方法 |
| AGC | 关闭 | 自动增益控制可能引入失真,当前场景不需要 |
| 内存分配 | 优先使用 PSRAM | AFE 模型较大,放在外部 PSRAM 节省内部 SRAM |
9.2 唤醒词检测(空闲阶段)参数
| 参数 | 值 | 原因 |
|---|---|---|
| AFE 类型 | SR(语音识别) | 集成唤醒词检测功能 |
| AEC 模式 | SR_HIGH_PERF | 为语音识别场景优化 |
| 优先核心 | Core 1 | AFE 任务固定在 Core 1,避免与其他关键任务争抢 Core 0 |
| 内存分配 | 优先使用 PSRAM | 模型数据放 PSRAM |
9.3 重采样器参数
| 参数 | 值 | 原因 |
|---|---|---|
| 复杂度 | 2 | 速度优先,嵌入式场景不追求极致音质 |
| 性能类型 | SPEED | 明确告知算法优先速度而非质量 |
| 位深 | 16bit | 与整条链路一致 |
10. 参数速查表
上行链路核心参数
| 参数 | 值 | 选择原因 |
|---|---|---|
| 采集采样率 | 16kHz(重采样后) | 语音模型标准、OPUS 编码器配置 |
| 采集位深 | 16bit 有符号整数 | 标准语音处理位深 |
| 采集通道 | 1~2(输出为 mono) | 最终编码为单声道 |
| 采集粒度 | 10ms(160 采样点) | 满足唤醒词和 AFE 引擎的喂入需求 |
| 编码帧长 | 60ms(960 采样点) | 压缩效率与嵌入式资源折中 |
| 编码格式 | OPUS | 低延迟、低码率、流式、上下行统一 |
| 编码码率 | Auto | 自适应内容 |
| 编码复杂度 | 0 | MCU 实时约束 |
| DTX | 开启 | 静默段省电省带宽 |
| VBR | 开启 | 语音动态范围大 |
| FEC | 关闭 | TCP 已可靠 / UDP 接受偶尔丢帧 |
| 编码队列上限 | 2 个 PCM 帧 | 控制内存,背压流控 |
| 发送队列上限 | ~2400ms(~40 个 OPUS 包) | 抗网络抖动,内存可控 |
| 唤醒词音频保留 | ~2 秒 | 供服务端做说话人识别/唤醒确认 |
11. 一句话总结
设备端麦克风采集 16kHz PCM → 本地唤醒词引擎检测触发 → 音频前端处理(AEC 消除回声 + NS 降噪 + VAD 检测语音活动)→ 干净 PCM 按 60ms 分帧 → OPUS 编码压缩 → 网络上传(WebSocket/UDP)→ 云端 OPUS 解码 → STT 语音识别引擎 → 识别文字返回设备显示。
全链路以 OPUS 16kHz/mono/60ms 为核心编码参数,与下行链路完全对称统一;唤醒词检测和音频前端处理作为两个独立模块分阶段运行,在低功耗待机和高质量语音上传之间取得平衡。