












LLM 文本 → TTS 语音 → OPUS 编解码 → 播放:完整技术链路
1. 文档目标
系统讲清楚以下链路涉及的业务流程、技术原理、背景知识以及每个参数为什么这样选:
LLM 文本 → TTS 语音合成 → OPUS 编码 → 网络传输 → OPUS 解码 → 扬声器播放本文不涉及具体代码实现,只讲业务流、技术原理和参数设计。
2. 整体业务流全景
2.1 完整链路图
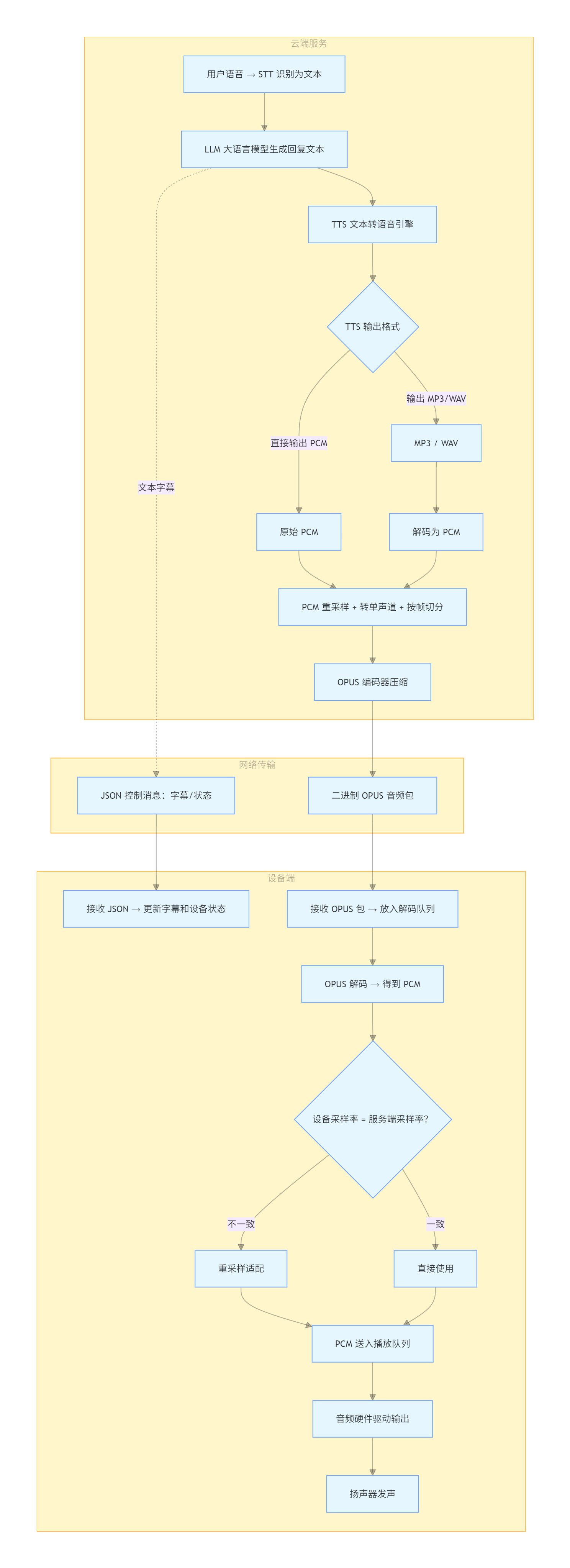
flowchart TD
%% 云端服务模块
subgraph 云端服务
A["用户语音 → STT 识别为文本"]
B["LLM 大语言模型生成回复文本"]
C["TTS 文本转语音引擎"]
D{"TTS 输出格式"}
D1["原始 PCM"]
D2["MP3 / WAV"]
D3["解码为 PCM"]
E["PCM 重采样 + 转单声道 + 按帧切分"]
F["OPUS 编码器压缩"]
end
%% 网络传输模块
subgraph 网络传输
G["JSON 控制消息:字幕/状态"]
H["二进制 OPUS 音频包"]
end
%% 设备端模块
subgraph 设备端
I["接收 JSON → 更新字幕和设备状态"]
J["接收 OPUS 包 → 放入解码队列"]
K["OPUS 解码 → 得到 PCM"]
L{"设备采样率 = 服务端采样率?"}
M["重采样适配"]
N["直接使用"]
O["PCM 送入播放队列"]
P["音频硬件驱动输出"]
Q["扬声器发声"]
end
%% 云端服务流程连线
A --> B
B --> C
C --> D
D -->|直接输出 PCM| D1 --> E
D -->|输出 MP3/WAV| D2 --> D3 --> E
E --> F
F --> H
B -.文本字幕.-> G
%% 网络传输 → 设备端流程连线
G --> I
H --> J
J --> K
K --> L
L -->|不一致| M --> O
L -->|一致| N --> O
O --> P
P --> Q2.2 核心要点
- LLM 只负责生成文本,不产出任何音频
- TTS 引擎在云端运行,把文本合成为语音
- OPUS 编码在云端完成,设备端只做解码和播放
- 设备同时收到两路数据:
- JSON 文本消息:用于屏幕字幕显示、控制设备状态机
- OPUS 二进制音频包:用于扬声器真正发声
- 这两路是并行的,不是串行的
3. 每个环节的技术原理
3.1 LLM 大语言模型
输入:用户的语音识别结果(文本)
输出:自然语言回复(纯文本字符串),例如 "今天天气晴,最高温度 26 度。"
关键特性:
- LLM 是流式输出的,一边生成 token 一边往下游推送
- TTS 不需要等整句话生成完才开始合成
- 流式能力直接决定了整条链路的首包延迟(用户说完话到听到回复的等待时间)
3.2 TTS 文本转语音
做什么
把 LLM 输出的文本转换成人声语音波形。
常见 TTS 输出格式对比
| 格式 | 本质 | 特点 |
|---|---|---|
| PCM | 未压缩原始采样 | 体积大,无需解码,零延迟 |
| WAV | PCM + 文件头 | 本质还是 PCM,多了 44 字节头 |
| MP3 | 有损压缩 | 广泛兼容,但编码延迟大(~100ms+) |
| OGG/Opus | 低延迟有损压缩 | 专为实时通信设计 |
| AAC | 有损压缩 | 苹果生态常用,需要授权费 |
为什么不直接把 TTS 原始输出发给设备
- PCM/WAV 太大:16kHz/16bit/mono PCM,每秒 32KB,10 秒对话 320KB,对嵌入式设备和窄带网络负担沉重
- MP3 延迟高:MP3 编码器帧延迟较大,不适合逐句流式场景
- 需要统一格式:设备上行(麦克风)和下行(语音回复)需要统一协议,避免维护两套编解码器
结论:无论 TTS 引擎输出什么格式,都在云端统一转换为 OPUS 再发给设备。
3.3 OPUS 编解码器
背景
OPUS 是由 IETF 标准化的开放音频编码格式(RFC 6716),专为实时互联网通信设计。WebRTC、Discord、Zoom、微信语音通话等产品的底层都使用 OPUS。
OPUS vs 其他编码对比
| 特性 | OPUS | MP3 | AAC | PCM |
|---|---|---|---|---|
| 算法延迟 | 2.5~60ms 可调 | ~100ms+ | ~20ms+ | 0ms |
| 码率范围 | 6~510 kbps | 32~320 kbps | 8~256 kbps | 固定 |
| 语音专项优化 | ✅ SILK 内核 | ❌ | ❌ | 不适用 |
| 帧长灵活性 | 2.5~120ms 多档 | 固定 26ms | 固定 ~21ms | 任意 |
| 丢包容忍 | 内置 FEC + PLC | 差 | 差 | 极差 |
| 流式友好 | 天生流式 | 需缓冲 | 需缓冲 | 天生流式 |
| 嵌入式适用 | 复杂度可调(0~10) | 解码较重 | 解码较重 | 无需解码 |
| 开源免版税 | ✅ | 专利已到期 | ❌ 需授权 | 不适用 |
OPUS 的内部结构
OPUS 是两个编码器的混合体:
┌──────────────────────────────────────┐
│OPUS 编码器│
││
│┌──────────┐┌───────────────┐│
││ SILK││ CELT││
││(语音) ││(音乐/通用)││
│└──────────┘└───────────────┘│
│ ↑↑│
│窄带/宽带语音 全频带音频│
│(人声为主)(音乐/混合)│
└──────────────────────────────────────┘- SILK 内核:源自 Skype,针对人声优化,低码率下语音清晰度极佳
- CELT 内核:源自 Xiph.org,针对全频带通用音频
- OPUS 会根据输入内容自动切换或混合两个内核
为什么 OPUS 特别适合 AI 语音助手
- 低延迟:对话要求自然流畅,OPUS 算法延迟远低于 MP3
- 低码率音质好:16kbps OPUS 语音质量 ≈ 64kbps MP3
- 帧长可调:可根据嵌入式设备处理能力选择合适帧长
- 复杂度可调:嵌入式 MCU 可以把复杂度设到最低,省 CPU
- 天然流式:收到一帧解码一帧,不需要缓冲整段音频
- 上下行统一:麦克风上传和语音下发共用同一套编解码器
3.4 网络传输
并行双通道
设备和服务端之间同时维持两个逻辑通道:
| 通道 | 内容 | 作用 |
|---|---|---|
| 控制通道 | JSON 文本消息 | 状态切换、字幕显示 |
| 音频通道 | OPUS 二进制包 | 真正的语音数据 |
两种传输方案
方案 A:WebSocket 全双工
设备 ◄══════ WebSocket ══════► 服务端
文本帧 (JSON)◄─────►
二进制帧 (OPUS) ◄─────►- 一条连接承载 JSON + 音频
- 基于 TCP,可靠传输
- 实现简单,延迟略高
方案 B:MQTT 控制 + UDP 音频
设备 ◄── MQTT/TLS ──► 服务端(JSON 控制,可靠)
设备 ◄── UDP/AES ───► 服务端(OPUS 音频,低延迟)- 控制走 MQTT/TLS:可靠、有 QoS
- 音频走 UDP + AES-128-CTR 加密:更低延迟
- 需要自行处理丢包和序列号校验
- 比 WebSocket 方案延迟更低,但实现更复杂
握手协商
设备连接时发送 hello 消息声明音频参数:
{"type": "hello","audio_params": {"format": "opus","sample_rate": 16000,"channels": 1,"frame_duration": 60}}服务端回复确认最终参数(可能微调采样率等),双方协商一致后音频通道正式开启。
一次完整的 TTS 消息时序
时间 ─────────────────────────────────────────────────────►
① {"type":"tts", "state":"start"}设备进入"播放"状态
② {"type":"tts", "state":"sentence_start", 屏幕显示字幕
"text":"今天天气晴"}
③ [OPUS包][OPUS包][OPUS包]... 扬声器播放这句话
④ {"type":"tts", "state":"sentence_start", 下一句字幕
"text":"最高温度 26 度"}
⑤ [OPUS包][OPUS包][OPUS包]... 播放下一句
⑥ {"type":"tts", "state":"stop"} 设备回到"空闲/聆听"文本消息和音频包是交替并行发送的,不是先发完所有文本再发音频。
3.5 设备端解码与播放
解码流程
OPUS 音频包到达
│
▼
检查采样率和帧长 → 必要时重新配置解码器
│
▼
OPUS 解码 → 得到 PCM(16bit 有符号整数)
│
▼
采样率匹配检查
│
├── 不一致 → 重采样适配硬件
└── 一致 → 直接使用
│
▼
送入播放队列
│
▼
音频硬件驱动(I2S / Codec 芯片)
│
▼
扬声器发声为什么需要重采样
- 服务端 TTS 可能输出 24kHz(高质量 TTS 常见)
- 设备硬件 Codec 可能只支持 16kHz 或 48kHz
- 重采样器作为兜底,让协议层保持灵活,不强绑固定采样率
三任务并行模型
设备端音频系统拆分为三个独立实时任务:
┌───────────────┐ ┌────────────────┐ ┌───────────────┐
│音频输入任务 │ │ 编解码任务│ │音频输出任务 │
│(最高优先级) │ │(中等优先级) │ │(较高优先级) │
│ │ ││ │ │
│麦克风采集│ │上行:│ │从播放队列取 │
│唤醒词检测│ │ PCM → OPUS │ │PCM 数据│
│语音前端处理 │ │下行:│ │写入音频硬件 │
│ │ │ OPUS → PCM │ │驱动扬声器│
└───────┬───────┘ └────────┬───────┘ └───────┬───────┘
│││
▼▼▼
编码队列 ──►解码/发送队列 ◄── 播放队列为什么这样拆分:
- 音频输入 优先级最高:麦克风必须实时采集,否则丢帧
- 编解码 单独任务:CPU 密集操作,不能阻塞 I/O
- 音频输出 独立运行:保证播放连续平滑,不被解码或网络抖动打断
为什么队列里存 OPUS 包而不是 PCM
同一个 60ms 音频帧的大小对比:
| 格式 | 大小 |
|---|---|
| PCM(16kHz/16bit/mono) | 960 采样 × 2 字节 =1920 字节 |
| OPUS 压缩后 | 通常40~120 字节 |
OPUS 包体积约为 PCM 的 1/15 ~ 1/50。在只有几百 KB 可用 RAM 的 MCU 上:
- 用更少内存缓冲更长时间的音频
- 减少内存分配压力
- 降低队列阻塞风险
3.6 本地提示音:另一条辅助链路
除了在线语音回复,设备还有本地提示音(如开机音、错误提示音)。
内置 OGG 音频资源(封装的也是 Opus)
│
▼
OGG 解封装 → 提取出 Opus 帧
│
▼
送入同一条解码队列
│
▼
复用完全相同的 OPUS 解码 → 播放链设计好处:在线语音和本地提示音共用同一套播放基础设施,不需要额外维护 MP3/WAV 解码器。
4. 参数选择详解
4.1 参数总览
| 参数 | 值 | 类别 |
|---|---|---|
| 编码格式 | OPUS | 传输格式 |
| 采样率 | 16000 Hz | 音频质量 |
| 通道数 | 1(单声道) | 音频质量 |
| 帧长 | 60 ms | 延迟与效率 |
| 码率 | 自动(Auto) | 压缩策略 |
| 复杂度 | 0(最低) | CPU 负载 |
| 前向纠错 FEC | 关闭 | 抗丢包 |
| 不连续传输 DTX | 开启 | 省电省带宽 |
| 可变码率 VBR | 开启 | 压缩效率 |
| 队列缓冲上限 | ~2400 ms | 流畅度 |
4.2 采样率:16000 Hz
背景
采样率决定可表达的最高频率(奈奎斯特定理:最高频率 = 采样率 / 2)。
| 采样率 | 最高频率 | 典型用途 |
|---|---|---|
| 8000 Hz | 4 kHz | 电话语音(窄带) |
| 16000 Hz | 8 kHz | 宽带语音、语音助手 |
| 24000 Hz | 12 kHz | 高质量 TTS |
| 48000 Hz | 24 kHz | 专业音频/音乐 |
选择原因
- 语音频带完整覆盖:人声基频 85~255 Hz,共振峰 300~3400 Hz,辅音能量到 ~8 kHz。16kHz 完整覆盖
- 语音模型标准:绝大多数 STT / TTS 模型以 16kHz 为标准
- 资源与质量甜点:比 8kHz 明显更清晰;比 24kHz/48kHz 节省一半以上带宽和处理量
- 嵌入式友好:ESP32 级 MCU 处理 16kHz 游刃有余,48kHz 就需要更大缓冲和更多 CPU
每秒数据量对比
| 采样率 | 每秒 PCM(16bit mono) | 每分钟 |
|---|---|---|
| 8 kHz | 16 KB | 960 KB |
| 16 kHz | 32 KB | 1.9 MB |
| 24 kHz | 48 KB | 2.8 MB |
| 48 kHz | 96 KB | 5.6 MB |
4.3 通道数:1(单声道)
- 语音助手不需要空间定位:不像音乐需要立体声
- 数据量减半:单声道 = 双声道的 50%
- 编解码负载减半
- 嵌入式设备通常单扬声器
- 队列内存减半:对 RAM 紧张的 MCU 至关重要
4.4 帧长:60ms
背景
OPUS 支持的帧长:2.5 / 5 / 10 / 20 / 40 / 60 / 80 / 100 / 120 ms
帧长决定了每次编解码处理的音频时长、每个网络包的大小、端到端延迟的下限。
帧长的权衡
短帧 (5~20ms)长帧 (60~120ms)
◄──────────────────────────────────────────────►
低延迟高延迟
高包率(网络开销大)低包率(网络开销小)
低压缩效率 高压缩效率
高CPU中断频率 低CPU中断频率
适合实时通话适合嵌入式/低功耗选择 60ms 的原因
| 维度 | 60ms 的表现 |
|---|---|
| 压缩效率 | 帧内统计冗余多,压缩率比 20ms 更高 |
| 网络包率 | 每秒 ~17 个包(vs 20ms 的 50 个包),减少包头开销 |
| CPU 调度 | 编解码每秒触发 ~17 次(vs 50 次),更省 CPU |
| 队列管理 | 同样缓冲区存放更长时间音频 |
| 延迟 | 60ms 帧延迟 + 网络 + 处理 ≈ 150~300ms,对话场景可接受 |
帧长对帧大小的影响
60ms,16kHz,mono:
- PCM 帧:16000 × 0.06 = 960 采样 × 2 字节 = 1920 字节
- OPUS 帧:压缩后约 40~120 字节
队列缓冲设计
项目将队列缓冲上限设为 ~2400ms,即约 2400 / 60 = 40 个 OPUS 包。
这个设计保证:
- 有足够缓冲应对网络抖动
- 不会因为缓冲过多导致延迟过大
- 内存占用可控(40 个 OPUS 包 ≈ 40 × 100 = 4KB,远小于 40 帧 PCM 的 77KB)
4.5 码率:自动(Auto)
什么是自动码率
让 OPUS 编码器根据当前帧的音频内容自动决定分配多少比特:
- 安静段 → 低码率
- 复杂语音段 → 高码率
- 过渡段 → 中等码率
为什么不手动指定固定码率
- 固定码率无法适应语音内容的动态变化
- 指定过高浪费带宽,指定过低损害音质
- 自动模式是 OPUS 官方推荐的语音场景默认值
- 对于语音助手这种内容不可预测的场景,自动模式最稳妥
4.6 复杂度:0(最低)
背景
OPUS 的 complexity 参数范围 0~10,控制编码器搜索最优压缩方案的努力程度:
| 复杂度 | CPU 占用 | 压缩效率 | 适用场景 |
|---|---|---|---|
| 0 | 最低 | 稍低 | 嵌入式设备 |
| 5 | 中等 | 较好 | 普通手机/PC |
| 10 | 最高 | 最优 | 服务器端/离线处理 |
选择 0 的原因
- 实时优先:MCU 必须在一帧时长(60ms)内完成编码,复杂度高可能超时
- 低功耗:智能硬件长期在线运行,省 CPU = 省电
- 可接受的质量差异:complexity 0 vs 10 在语音场景下的主观音质差异很小(OPUS 本身在语音上已经很好)
- 只影响编码端:设备端上行编码用 0,服务端下行编码可以用更高值
4.7 前向纠错 FEC:关闭
什么是 FEC
Forward Error Correction,编码时在当前包中嵌入前一包的冗余信息。如果前一包丢失,解码器可以从当前包中恢复它。
开启 FEC 的代价
- 码率增加约 50%
- 编码计算量增加
- 引入额外延迟
为什么关闭
- WebSocket 方案基于 TCP:TCP 本身保证可靠传输,不会丢包
- UDP 方案更依赖轻量低延迟:靠序列号检测丢包,接受偶尔丢帧,而不是增加冗余开销
- 语音对话场景容忍偶尔丢帧:人耳对短暂(60ms)的语音缺失不太敏感,OPUS 解码器内置 PLC(包丢失隐藏)可以平滑过渡
4.8 不连续传输 DTX:开启
什么是 DTX
Discontinuous Transmission,当检测到输入是静音或背景噪声时,编码器停止发送或只发极小的静音描述包。
开启的好处
- 省带宽:对话中大量时间是"无人说话"的静默段
- 省电:不编码不发送 = CPU 空闲 + 无线模块休眠
- 减轻服务端压力:无效音频不传输
- 长期在线设备尤其受益:语音助手 90% 以上的时间处于待命/静音状态
注意事项
- DTX 只影响上行(麦克风 → 服务端),下行 TTS 语音通常无大段静默
- 恢复说话时有极短的首帧延迟(通常 <20ms),对对话体验无感知影响
4.9 可变码率 VBR:开启
什么是 VBR
Variable Bit Rate,每一帧根据内容复杂度动态分配不同的码率。
与 CBR(Constant Bit Rate,固定码率)对比:
| 模式 | 特点 |
|---|---|
| VBR | 安静段省码率,复杂段多给码率,整体更高效 |
| CBR | 每帧码率固定,简单可预测,但压缩效率较低 |
选择 VBR 的原因
- 语音的动态范围大:元音能量高,辅音能量低,静默无能量
- VBR 能把码率花在刀刃上
- OPUS 官方推荐语音场景使用 VBR
- 配合 DTX,静默段几乎零码率
4.10 解码端重采样
为什么存在
服务端 TTS 输出的采样率和设备硬件 Codec 的工作采样率不一定相同。例如:
- 服务端 TTS 输出 24kHz(高质量 TTS 常见)
- 设备端 Codec 芯片运行在 16kHz
工作方式
- 设备在握手阶段收到服务端确认的采样率
- 如果与本机硬件采样率不一致,启动重采样器
- 重采样在 OPUS 解码之后、写入硬件之前执行
设计好处
- 协议层保持灵活,不硬编码某一个采样率
- 板级硬件差异被隔离在最后一环
- 未来服务端升级 TTS(如从 16kHz 升到 24kHz)不需要改设备固件
5. 上行链路:为什么也要了解
虽然主题是"文本到播放"(下行),但理解上行链路有助于理解参数为什么这样统一设计。
上行业务流
麦克风采集 → 语音前端处理(降噪/回声消除) → PCM 分帧 → OPUS 编码 → 网络发送 → 服务端 STT上下行参数统一的好处
- 协议统一:上下行用同一种音频格式,简化协议设计
- 编解码器复用:设备只维护一套 OPUS 编解码器
- 队列结构复用:帧长一致,队列管理逻辑通用
- 内存可预测:统一帧大小,内存分配可预算
- 服务端处理简化:收发都是 OPUS,无需多格式适配
6. MP3/WAV 与当前架构的关系
6.1 当前架构的真实情况
- 在线音频协议声明的格式是
opus,不是 MP3 也不是 WAV - 设备端只包含 OPUS 编解码器,没有 MP3/WAV 解码器
- 本地提示音也是 OGG(Opus) 封装,不是 MP3/WAV
结论:当前项目在线语音回复链路不涉及 MP3/WAV。
6.2 如果上游 TTS 输出 MP3/WAV 怎么办
推荐做法:在服务端完成转换
TTS 输出 MP3/WAV
│
▼ (服务端)
解码为 PCM → 重采样到 16kHz/mono → 按 60ms 分帧 → OPUS 编码
│
▼ (网络)
发给设备 → 设备端正常 OPUS 解码 → 播放为什么不在设备端解码 MP3/WAV:
| 因素 | 服务端转换 | 设备端解码 |
|---|---|---|
| CPU 负载 | 服务端资源充裕 | MCU 负担重 |
| 内存占用 | 不影响设备 | 需额外解码器内存 |
| 网络带宽 | OPUS 传输,带宽最优 | MP3/WAV 直传,带宽浪费 |
| 实时性 | OPUS 天生流式 | MP3 需要缓冲 |
| 维护成本 | 设备端无需改动 | 需新增解码器和适配 |
| 架构一致性 | 保持统一 | 引入异构路径 |
7. 完整参数速查表
| 参数 | 值 | 选择原因 |
|---|---|---|
| 格式 | OPUS | 低延迟、低码率语音好、流式、免版税、嵌入式友好 |
| 采样率 | 16kHz | 语音频带甜点、STT/TTS 标准、嵌入式可承受 |
| 通道 | Mono | 语音不需立体声、省一半资源 |
| 帧长 | 60ms | 压缩效率与延迟的折中、嵌入式省 CPU 省内存 |
| 码率 | Auto | 自适应内容、OPUS 推荐默认值 |
| 复杂度 | 0 | MCU 实时约束、省电、语音下音质差异小 |
| FEC | 关闭 | TCP 已可靠、UDP 接受偶尔丢帧、省码率 |
| DTX | 开启 | 静默段省电省带宽、长期在线设备必备 |
| VBR | 开启 | 语音动态范围大、码率花在刀刃上 |
| 队列缓冲 | ~2400ms | 抗网络抖动、不过度延迟、内存可控 |
8. 一句话总结
云端 LLM 生成文本 → 云端 TTS 合成语音 → 云端 OPUS 编码压缩 → 网络传输(JSON 字幕 + OPUS 音频并行)→ 设备端 OPUS 解码为 PCM → 必要时重采样 → 音频硬件驱动 → 扬声器发声。
全链路以 OPUS 16kHz/mono/60ms 为核心,在延迟、码率、音质、嵌入式资源之间取得最优平衡。